 This project is about a bank which has a growing customer base where the majority of customers are depositors with
varying size of deposits. Apart from the majority of customers that are depositors, several customers are also borrowers
(asset customers). The bank planned to expand the asset customers to earn more through the interest on personal loans by
converting the depositors (potential customers) to personal loan customers while retaining them as depositors. A campaign
that the bank ran last year for potential customers showed a healthy conversion rate of over 9% success. This has
encouraged the retail marketing department to devise campaigns for better target marketing that will increase the
success ratio while at the same time reduce the cost of the campaign by using a model that will help them identify the
potential customers who have a higher probability of purchasing the loan.
This project is about a bank which has a growing customer base where the majority of customers are depositors with
varying size of deposits. Apart from the majority of customers that are depositors, several customers are also borrowers
(asset customers). The bank planned to expand the asset customers to earn more through the interest on personal loans by
converting the depositors (potential customers) to personal loan customers while retaining them as depositors. A campaign
that the bank ran last year for potential customers showed a healthy conversion rate of over 9% success. This has
encouraged the retail marketing department to devise campaigns for better target marketing that will increase the
success ratio while at the same time reduce the cost of the campaign by using a model that will help them identify the
potential customers who have a higher probability of purchasing the loan.
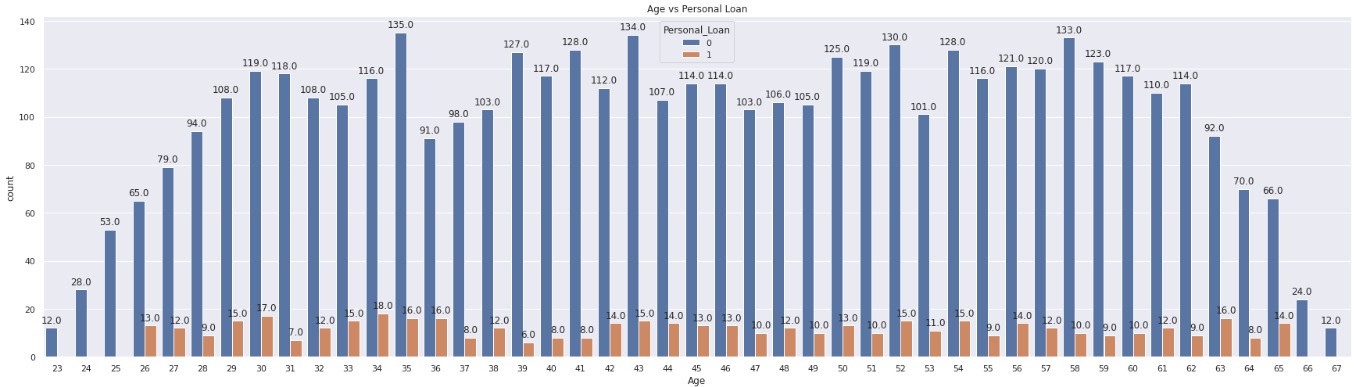
Based on the problem, I perform exploratory data analysis to analyze the dataset and to find outwhat features influence potential customers to convert to personal loan customers. Based on the exploratory data analysis results, it is shown that the target label data (Personal_Loan) is imbalanced, so it needs weighting and scored by f1 score metrics. The plot shown below shows that education level, income, and credit card spending cost average per month are the three features among several other features that influenced the customer’s decision. From the education plot, it shows that the higher customer’s education level, the more likely the customers having a personal loan, yet it shows that overall the customers still tend to not having a personal loan although they having a high education level. The income-related plot also shows that the customers that having an annual income above mean are more likely to purchase the loan. Three algorithms were selected as the model algorithm, namely Logistic Regression, Random Fores Classfier, and XGBoost Classifier. Based on the hyperparameter tuning result and classification metrics, it shows that the random forest classifier model is the best model to use for incoming real data prediction.
This project’s GitHub repository
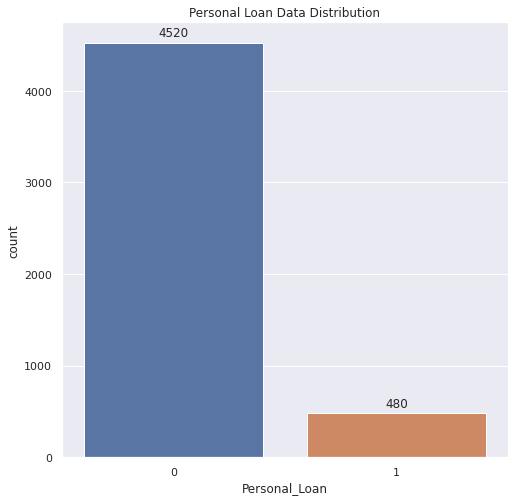 Figure 1. Target data
Figure 1. Target data
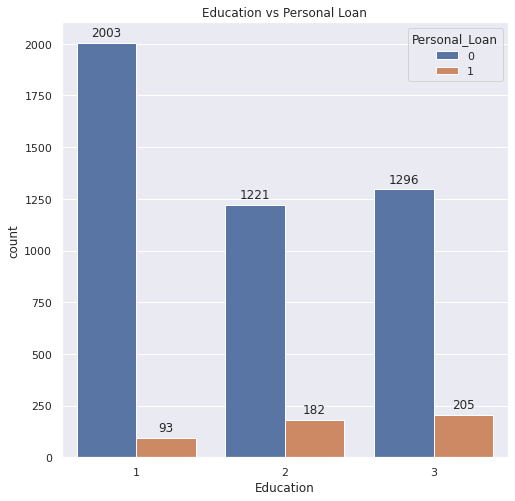 Figure 2. Education and personal loan plot
Figure 2. Education and personal loan plot
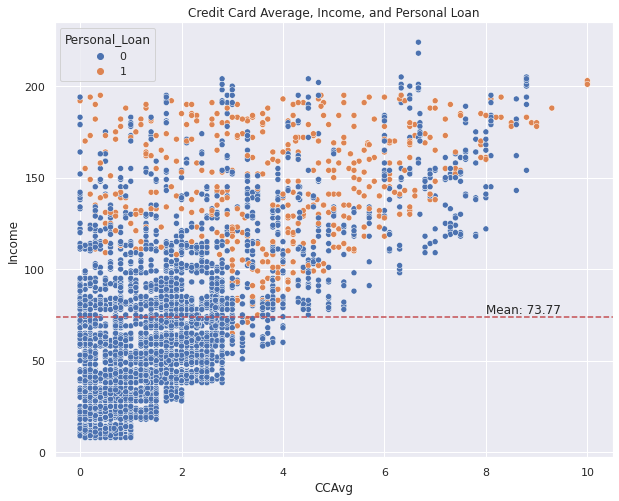 Figure 3. Average credit card spending cost (per month) and personal loan plot
Figure 3. Average credit card spending cost (per month) and personal loan plot
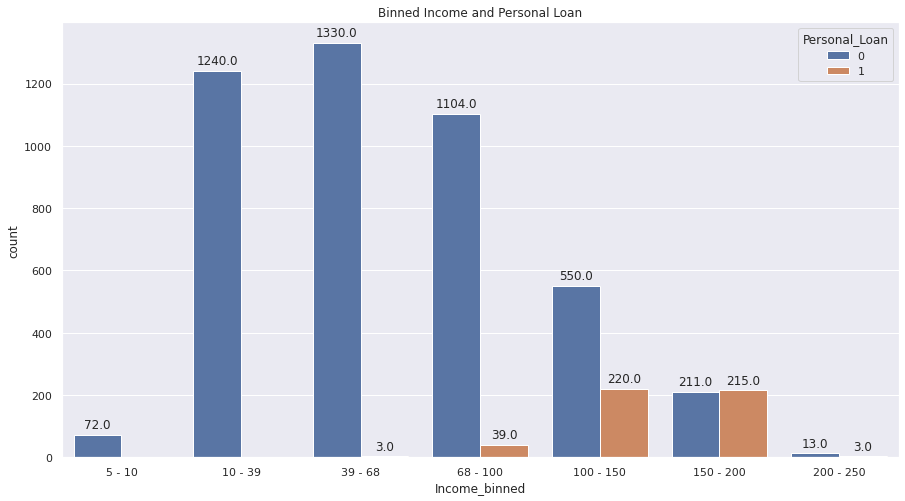 Figure 4. Binned income and personal loan plot
Figure 4. Binned income and personal loan plot
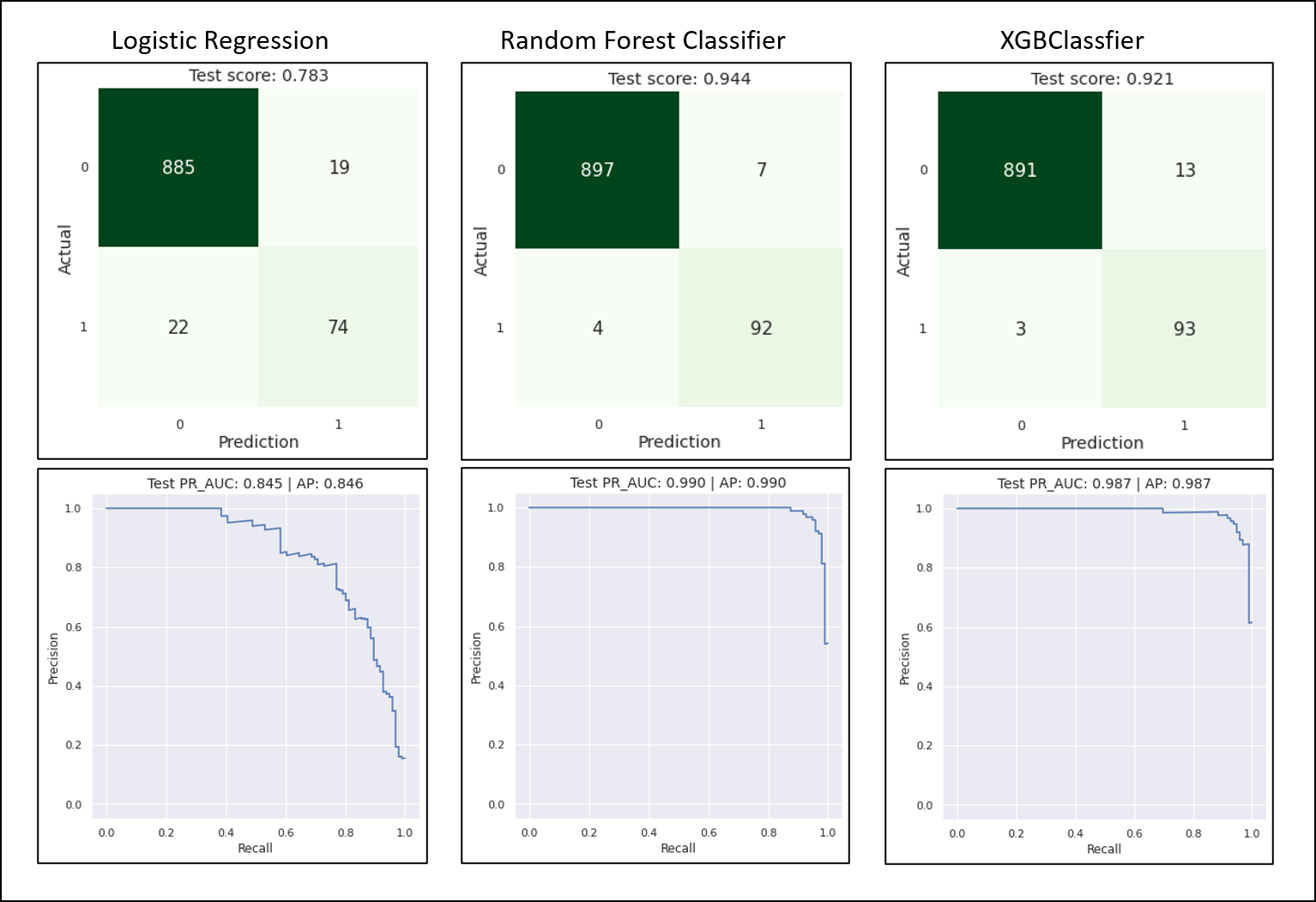 Figure 5. Confussion matrix and precission-recall area under curve plot
Figure 5. Confussion matrix and precission-recall area under curve plot